
工具
当前位置:首页 > 成果 > 工具音段自动切分与标注工具:xSegmenter
发布时间:3/3/2026 12:55:47 PM
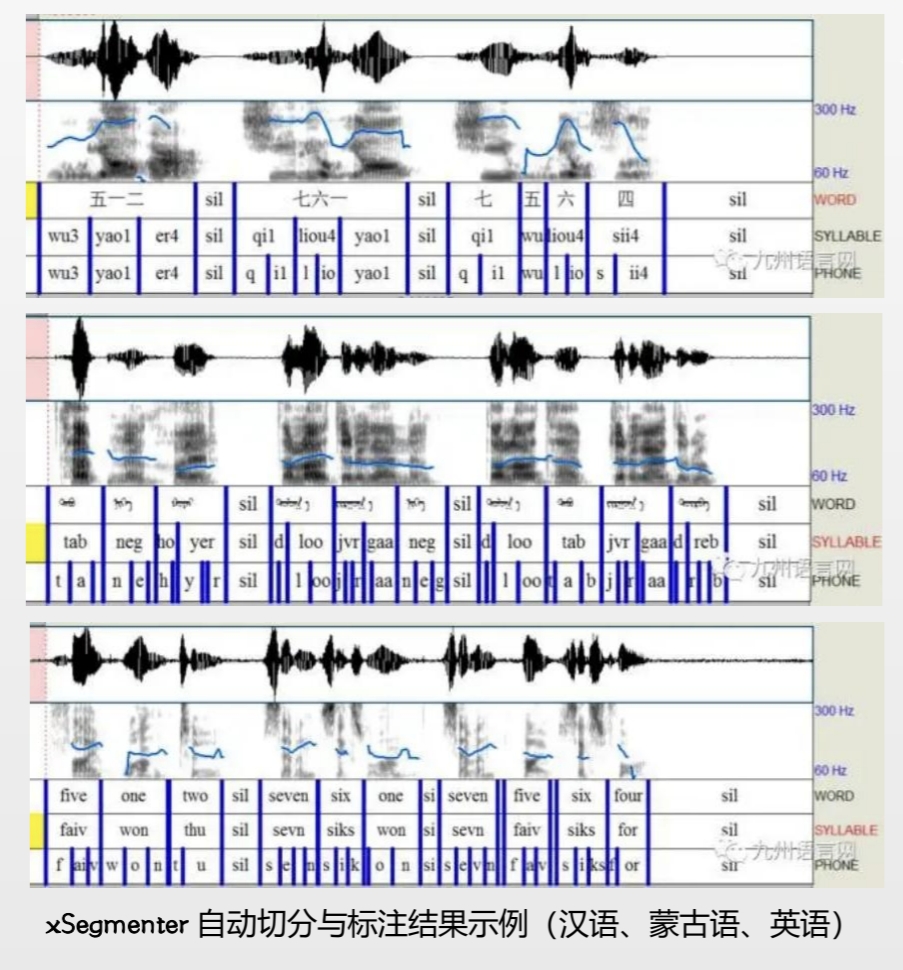
xSegmenter 旨在解决语音语料库建设过程中的音段标注效率和一致性问题 ,该工具基于用户所提供的语料及相关资源训练生成单音素声学模型 , 然后进行音段强制对齐和标注 , 最后针对每个声音文件转写生成相应的语音标注文件 ,可包括词语层、音节层和音素层等标注内容。
作者:熊子瑜
主要特色:
由于该工具自身不提供任何声学模型和词典 ,而是基于用户所提供的声音文件 、 带有分词信息的发音文本文件和发音词典文件等数据资源自动训练生成相应的语音声学模型 , 然后再利用所生成的语音声学模型去完成音段对齐任务 ,因此这一工具可适用于任意语言和方言的语音库建设。
物料: 声音文件 + 发音文本文件 + 发音词典
过程: 训练 + 切分 + 标注
结果:TextGrid 标注文件
链接:https://pan.cass.cn/disk/s/NfNkvvJRRPL?pwd=116805&domainId=bj17093
密码:116805
相关链接
- 中国社科院语言所 |
- 中国语言学会 |
- 中国语言学会语音学分会 |
- 语音与言语科学实验室 |
- 《当代语言学》期刊 |
- 《中国语音学报》期刊 |
联系我们
中国社会科学院(中国社会科学院大学)语言学重点实验室
电话:010-85195394 邮箱:kyc_yys@cass.org.cn北京市房山区良乡高教园区长于大街11号中国社会科学院大学综合楼1层南侧
北京市东城区建国门内大街5号中国社会科学院语言研究所